ELIAS
ELIAS est le service Elasticsearch du CC-IN2P3. Il vous permettra d’optimiser vos recherches textuelles via Elasticsearch et de les visualiser sous la forme de graphiques organisés en tableaux de bord grâce aux outils Kibana et Grafana. De plus une API REST est disponible.
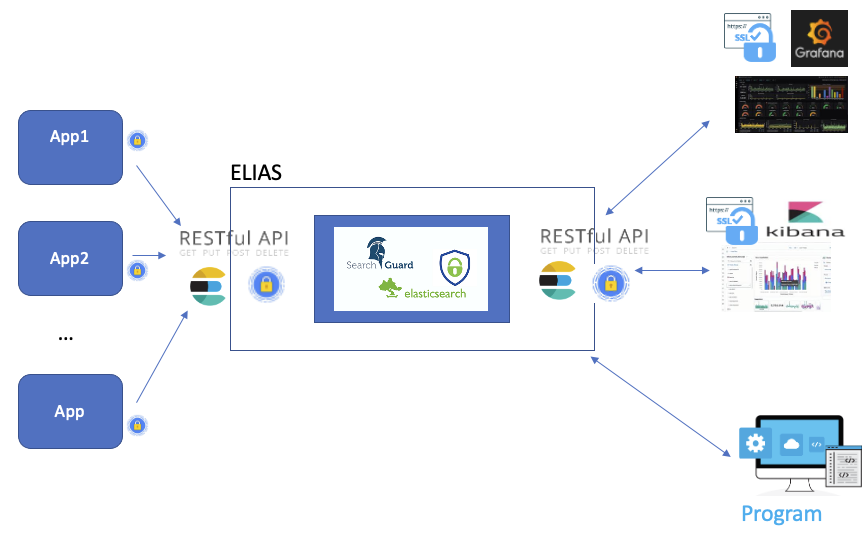
Selon l’utilisation de la plateforme, nous proposons différents types d’hébergement :
un cluster générique partagé ;
un cluster dédié en cas de spécificités particulières.
Pour demander un accès, merci de contacter le support utilisateurs. En cas de besoin particulier, précisez-le dans votre demande (contexte, raison et demande de ressources) comme pour les demandes de base de données.
Un espace sur ELIAS (namespace) vous sera alors attitré avec la possibilité d’y associer un ou plusieurs comptes d’accès (humain ou robot).
Note
L’URL d’accès à votre cluster ELIAS sera sous la forme :
elias-${CLUSTERNAME}.cc.in2p3.fr
La variable $CLUSTERNAME dépend du cluster sur lequel est hébergé l’utilisateur. La valeur de cette variable sera indiquée à l’utilisateur avec ses identifiants.
Accéder à la plateforme
Tous les services inclus dans ELIAS s’appuient sur un système d’authentification centralisé et supportent plusieurs méthodes selon le type de comptes.
Types de comptes
Un compte (utilisateur ou robot) est associé à une ou plusieurs méthodes d’authentification et dispose d’un ensemble de privilèges.
Les comptes utilisateur seront identifiés par:
Kerberos ;
Keycloack ;
login / mot de passe.
Les comptes robot seront identifiés par:
certificat client ;
login / mot de passe.
Une bonne pratique est d’associer un compte robot par machine cliente quand cela est possible. Pour des raisons de sécurité, nous recommandons l’utilisation de comptes spécifiques pour toute machine extérieure au CC-IN2P3.
Methodes d’accès
Cette méthode est à privilégier pour l’utilisation interactive, par exemple :
Session sur votre machine de travail ;
Session linux sur un serveur interactif.
Pour bénéficier d’une authentification par Kerberos, il vous suffit de disposer d’un compte calcul, et de l’avoir correctement configuré.
Après une requête simple (par exemple un curl) :
% curl --negotiate -u: https://elias-elias-${CLUSTERNAME}.cc.in2p3.fr.cc.in2p3.fr:9200/
la liste des tickets Kerberos devrait ressembler à :
% klist
Ticket cache: FILE:/tmp/krb5cc_1234_RrLMgX8bak
Default principal: username@CC.IN2P3.FR
Valid starting Expires Service principal
05/12/2020 10:49:33 05/15/2020 09:07:56 krbtgt/CC.IN2P3.FR@CC.IN2P3.FR
05/12/2020 10:50:30 05/15/2020 09:07:56 HTTP/ccosvmse0007.in2p3.fr@
05/12/2020 10:50:30 05/15/2020 09:07:56 HTTP/ccosvmse0007.in2p3.fr@CC.IN2P3.FR
La machine apparaissant comme service principal HTTP/... correspond au point d’entrée au service ELIAS.
Cette méthode est à privilégier pour l’accès à Kibana / Grafana et repose sur le système d’authentification du CC-IN2P3. Pour bénéficier de cette méthode d’authentification, il vous suffit de disposer d’un compte calcul.
Les certificats permettent de vous authentifier et de sécuriser les échanges entre le client et le serveur. Cette méthode est à privilégier pour les interactions automatisées telles que :
Tâche planifiée (cron) ;
Job dans la ferme de calcul ;
Importation de données (DAQ).
La plateforme ELIAS dispose de sa propre autorité de certification par conséquent il vous faudra télécharger le trousseau CA-ELIAS et l’importer dans votre système d’exploitation, votre navigateur ou votre application.
Pour demander votre accès par certificat, merci de suivre la procédure en fonction du système d’exploitation utilisé. La procédure est à appliquer sur la machine cible, c’est à dire la machine qui utilisera le certificat. Elle ne doit pas être appliquée sur une autre machine.
Générer une clé privée rsa
% openssl genrsa -out myelias.key 2048
Générer le CSR (Certificate Signing Request) :
% openssl req -new -key ${ROBOT}.key -out ${ROBOT}.csr You are about to be asked to enter information that will be incorporated into your certificate request. What you are about to enter is what is called a Distinguished Name or a DN. There are quite a few fields but you can leave some blank For some fields there will be a default value, If you enter '.', the field will be left blank. ----- Country Name (2 letter code) [AU]:FR State or Province Name (full name) [Some-State]:RHONE Locality Name (eg, city) []:Lyon Organization Name (eg, company) [Internet Widgits Pty Ltd]:CNRS Organizational Unit Name (eg, section) []:CC-IN2P3 Common Name (e.g. server FQDN or YOUR name) []: <compte ELIAS> Email Address []: Please enter the following 'extra' attributes to be sent with your certificate request A challenge password []: An optional company name []:
Attention
Pour des raisons d’uniformisation, nous recommandons de respecter les règles suivantes pour la clé Common Name :
<compte ELIAS> = <namespace> + <machine> + <application name>
Si vous souhaitez utiliser votre certificat pour plusieurs machines utilisez le pattern suivant :
<compte ELIAS> = <namespace> + <application name>
Pour les autres champs Organization, Organizational Unit ceux-ci sont optionnels et peuvent être personnalisées sans contrainte.
Envoyez le fichier avec l’extension
.reqà eliasmaster@cc.in2p3.fr .Attention
N’envoyez en aucun cas la clé
${ROBOT}.keypar mail. La clé ne doit jamais transiter par le réseau et rester uniquement sur la machine sur laquelle elle a été générée.Votre certificat signé par la CA vous sera ensuite envoyé par mail.
Installer le composant powershell en vérifiant que la commande
certreq.exeest bien disponible.Créer un fichier
request.infavec les informations suivantes :[Version] Signature= "$Windows NT$" [NewRequest] Subject = "CN=<compte ELIAS>, OU=IN2P3, O=CNRS, C=FR" KeySpec = 1 KeyLength = 4096 Exportable = TRUE MachineKeySet = TRUE SMIME = False PrivateKeyArchive = FALSE UserProtected = FALSE UseExistingKeySet = FALSE ProviderName = "Microsoft RSA SChannel Cryptographic Provider" ProviderType = 12 RequestType = PKCS10 KeyUsage = 0xa0 [EnhancedKeyUsageExtension] OID=1.3.6.1.5.5.7.3.2
Attention
Pour des raisons d’uniformisation, nous recommandons de respecter les règles suivantes pour la clé Subject :
<compte ELIAS> = <namespace> + <machine> + <application name>
Si vous souhaitez utiliser le certificat pour plusieurs machines utilisez le pattern suivant :
<compte ELIAS> = <namespace> + <application name>
Pour les champs OU, O et C ceux-ci sont optionnels et peuvent être personnalisés sans contrainte
Générer une demande de signature de certificat
certreq.exe -New request.inf ${ROBOT}.req
Envoyez le fichier
${ROBOT}.reqà eliasmaster@cc.in2p3.fr .Votre certificat signé par la CA vous sera ensuite envoyé par mail.
Attention
Il est fortement recommandé d’éviter ce type d’authentification pour des raisons de sécurité.
Pour le login (<username>), nous vous recommandons de suivre la syntaxe suivante :
<username> = <namespace> + <nom de l'application>
Les services inclus dans ELIAS
L’API REST est une interface qui permet les échanges de données entre services web. En tant que client de l’API, vous utiliserez les appels HTTP (GET, POST, PUT, …). Pour accéder à l’API REST, vous devrez vous authentifier par l’une des méthodes suivantes :
Pour plus d’informations, consultez les paragraphes suivantes :
Kibana est une interface graphique adaptée à l’analyse de données textuelles (par exemple : fichiers de logs). Vous pouvez construire des graphes sur la base d’une recherche textuelle pour constituer votre tableau de bord. Pour accéder à Kibana, vous devez disposer d’un compte calcul.
En tant qu’utilisateurs ELIAS vous trouverez votre service Kibana à l’URL suivant :
elias-${CLUSTERNAME}.cc.in2p3.fr
La variable $CLUSTERNAME dépendra du cluster sur lequel vous serez hébergés.
Grafana est une interface graphique adaptée à l’analyse de données numériques en séries temporelles. Grafana utilise la notion de tableau de bord pour agencer un ensemble de métriques sur une même page. Pour accéder à Grafana, vous devez disposer d’un compte calcul.
En tant qu’utilisateurs ELIAS vous trouverez votre service Grafana à l’URL suivant :
elias-${CLUSTERNAME}.cc.in2p3.fr:4443/
La variable $CLUSTERNAME dépendra du cluster sur lequel vous serez hébergés.
Ingestion des données
L’ingestion de vos données dans ELIAS est possible uniquement au travers de l’API REST.
L’API REST peut être exploitée par des librairies haut-niveau, dont certaines sont maintenues par elastic.co, ou via les commandes curl, wget, httpie, …
Pour stocker vos données, trois approches sont possibles :
commandes en ligne (
curl) (pratique pour une première prise en main) ;agent dédié (Fluentbit, logstash, syslog-ng, …) ;
votre propre script utilisant des librairies haut-niveau.
Vous pouvez utiliser les options suivantes pour indiquer la méthode d’authentification :
% kinit
% curl -u: --negotiate --cacert /path/to/elias.ca -H 'Content-Type: application/json' ...
% curl --key /path/to/mycertificate.pkey --cert /path/to/mycertificate.crt --cacert /path/to/elias.ca -H 'Content-Type: application/json' ...
% curl -u mylogin:mypwd --cacert /path/to/elias.ca -H 'Content-Type: application/json' ...
Elasticsearch enregistre les données dans un index comparable à une table dans les bases de données relationnelle. La commande suivante se connecte via un certficat et crée un index nommé mynamespace-myindexname.
% curl -XPUT 'https://elias-${CLUSTERNAME}.cc.in2p3.fr:9200/mynamespace-myindexname?pretty' --key /path/to/mycertificate.pkey --cert /path/to/mycertificate.crt --cacert /path/to/elias.ca -H 'Content-Type: application/json'
Attention
Le nom des indices doit respecter la syntaxe suivante : <namespace>-<index>. Vous pouvez créer autant d’indices que vous le souhaitez sous votre espace ELIAS.
Le nom du namespace est imposé par les administrateurs et vous est communiqué lors de la création de votre compte.
Un index Elasticsearch manipule uniquement des documents JSON. Un document est une collection de tuples clé/valeur et c’est l’unité la plus petite que manipule Elasticsearch. Il est possible de stocker des documents avec des structures de données complètement hétérogènes (sous certaines conditions).
Elasticsearch construit le schéma au fur et à mesure que les documents arrivent. Toutefois, il est possible d’imposer une structure de données explicite en configurant le mapping.
L’exemple ci-dessous associe une structure minimale que les documents de l’index mynamespace-myindexname doivent respecter.
% curl -XPUT --key /path/to/mycertificate.pkey --cert /path/to/mycertificate.crt --cacert /path/to/elias.ca -H 'Content-type: application/json' -XPUT 'http://localhost:9200/test3/_mapping' -d
'{
"dynamic_templates": [
{
"template_stdField": {
"path_match": "*",
"mapping": {
"ignore_malformed": true,
"type": "keyword"
}
}
}
],
"properties": {
"user_name": {
"type": "text"
}
}
}'
La commande suivante définit un mapping explicite pour l’indexe mynamespace-myindexname.
% curl -XPUT --key /path/to/mycertificate.pkey --cert /path/to/mycertificate.crt --cacert /path/to/elias.ca -H 'Content-Type: application/json' 'https://elias-${CLUSTERNAME}.cc.in2p3.fr:9200/mynamespace-myindexname/_mapping' -d @"my_mapping.json"
my_mapping.json{
"dynamic_templates": [
{ -
"template_stdField": {
"path_match": "*",
"mapping": {
"ignore_malformed": true,
"type": "keyword"
}
}
}
],
"properties": {
"user_name": {
"type": "text"
}
}
}
Attention
Le mapping explicite peut rejeter les documents non-conformes avec l’option ignore-malformed.
Note
Pour plus d’informations sur le mapping veuillez vous référer à la documentation officielle.
La commande suivante se connecte à ELIAS par certificat et crée un premier document dans l’index kafka-testoal :
% curl -XPOST 'https://elias-${CLUSTERNAME}.cc.in2p3.fr:9200/kafka-testoal/_doc/1/_create' --key /path/to/mycertificate.pkey --cert /path/to/mycertificate.crt --cacert /path/to/elias.ca -H 'Content-Type: application/json' -d '{ "user_name" : "John Doe" }'
Pour consulter une partie des documents d’un index, on pourra utiliser la commande suivante :
% curl -XGET 'https://elias-${CLUSTERNAME}.cc.in2p3.fr:9200/kafka-testoal//_search?pretty' --key /path/to/mycertificate.pkey --cert /path/to/mycertificate.crt --cacert /path/to/elias.ca -H 'Content-Type: application/json'
Note
Dans le cas d’une recherche avancée, veuillez vous référer au paragraphe Consulter les donnnées.
Un agent est un programme dont l’objectif est de collecter de l’information à partir de différentes sources et de rediriger le flux vers une destination de votre choix.
Les différentes sources de données et la destination seront à configurer au niveau de l’agent après son installation.
Exemple d’utilisation de l’agent Fluentd :

Les agents intègrent nativement un ensemble de fonctionnalités pour le traitement de vos sources de données les plus connues.
Quant à la redirection du flux d’information, il vous suffira de préciser comme destination ELIAS.
Il existe une multitude d’agents propriétaires et opensource comme:
Le support des agents n’est pas fourni par les administrateurs du service. Pour une mise en place facile et rapide nous vous conseillons de regarder Fluentbit.
Pour plus d’information vous pouvez vous référer au paragraphe Superviser votre machine.
Si vous avez développé votre propre application ou vous avez des besoins spécifiques qui ne peuvent être comblés avec un agent, vous avez la possibilité de vous interfacer avec ELIAS soit en utilisant une librairie haut-niveau propre à votre langage (recommandé), soit directement via l’API.
Le site officiel propose une liste non-exhaustive de librairies.
L’exemple ci-dessous illustre un script python qui se connecte par certificat et interagit avec la plateforme. Veillez à utiliser un environnement virtuel afin de sauvegarder le python de votre système.
Une fois l’environnement virtuel
<venv>créé et activé, installez-y la librairie officielle Elasticsearch :% pip install elasticsearch==7.10 certifi
Utilisez la librairie
certifipour localiser l’emplacement des CA autorisées pour python :>>> import certifi >>> certifi.where() '/<chemin>/<venv>/lib/python3.9/site-packages/certifi/cacert.pem'
Charger le trousseau CA-ELIAS dans le fichier
cacert.pem:% cat elias.ca >> /<chemin>/<venv>/lib/python3.7/site-packages/certifi/cacert.pem
Vous pouvez à présent vous authentifier par certificat avec python.
Vous trouverez ci-dessous quelques instructions pour vos débuts avec ELIAS :
#!/usr/bin/env python3
from elasticsearch import Elasticsearch
from datetime import datetime
import certifi
es = Elasticsearch('https://elias-${CLUSTERNAME}.cc.in2p3.fr:9200', timeout=120, use_ssl=True, verify_certs=True, client_cert='/<chemin>/elias/<namespace>-<host>-<username>.crt',ca_certs=certifi.where(),client_key='/<chemin>/elias/<namespace>-<host>-<username>.pkey')
## Permet d'afficher l'état du cluster
es.cluster.health()
## Création d'un index repectant la nomenclature <namespace>-<index>
es.indices.create(index='mynamespace-myindexname')
## Vérification du mapping de l'index
## L'index dispose d'un mapping dynamique,
## Le moteur d'Elasticsearch décrit la structure des documents au fur et à mesure de leur insertion
current_mapping = es.indices.get_mapping('mynamespace-myindexname')
print(current_mapping)
## Insertion d'un document dans un index
mydoc1 = {
'message': 'ERROR : This message contains some data about my application ',
'IP': "192.168.56.152",
'client': "java"
}
mydoc2 = {
'message': 'CRITICAL : This message is a warning from my application ',
'IP': "192.168.56.201",
'client': "python"
}
myindexeddoc = es.index(index="mynamespace-myindexname",id="2022-08-09 16:39:11.052116",body=mydoc1)
myindexeddoc = es.index(index="mynamespace-myindexname",id="2022-08-10 17:49:11.058455",body=mydoc2)
## Le mapping est automatiquement mis à jour
current_mapping = es.indices.get_mapping('mynamespace-myindexname')
print(current_mapping)
## lister l'ensemble de vos indices dans votre namespace
indices_dict = es.indices.get_alias("mynamespace-*")
for index_name, value in indices_dict.items():
print ('index: ', index_name)
## Rechercher un document par son identifiant
print(es.get(index="mynamespace-myindexname", id="2022-08-09 16:39:11.052116"))
## Rechercher un document avec des conditions
research = {
"query": {
"term": {
"message": "application"
}
}
}
resp = es.search(body=research ,index="mynamespace-myindexname")
print(resp)
## Limiter la projection des données
resp = es.search(body=research ,index="mynamespace-myindexname",filter_path=['hits.hits._id', 'hits.hits._source.message'])
## Supprimer un index
es.indices.delete(index="mynamespace-myindexname")
Consulter vos données
Pour consulter vos données, ELIAS propose différentes interfaces selon vos besoins :
Avec Elasticsearch vous avez la possibilité d’effectuer des recherches exactes par l’intermédiaire de filtres ou des recherches dites floues dans le sens où les critères peuvent être complètement ou partiellement respectés.
Exemples :
recherche les documents contenant obligatoirement les mots application et contains.
% curl -GET --key /path/to/mycertificate.pkey --cert /path/to/mycertificate.crt --cacert /path/to/elias.ca -H 'Content-Type: application/json' 'https://elias-${CLUSTERNAME}.cc.in2p3.fr:9200/mynamespace-myindexname/_search' -d @"filter_query.json"
filter_query.json{
"query": {
"bool": {
"must": [
{ "match": { "message": "application" }},
{ "match": { "message": "contains" }}
]
}
}
}
recherche les documents contenant obligatoirement les mots application et contains et potentiellement le mot warning.
% curl -GET --key /path/to/mycertificate.pkey --cert /path/to/mycertificate.crt --cacert /path/to/elias.ca -H 'Content-Type: application/json' 'https://elias-${CLUSTERNAME}.cc.in2p3.fr:9200/mynamespace-myindexname/_search' -d @"filter_query.json"
filter_query.json{
"query": {
"bool": {
"must": [
{ "match": { "message": "application" }},
{ "match": { "message": "contains" }}
],
"should": [
{ "match": { "message": "warning" }}
]
}
}
}
Elasticsearch implémente un langage de requête connu sous le nom de Elasticsearch DSL (Domain Specific Language). Ce langage permet d’exprimer des requêtes avec des conditions complexes en utilisant des opérateurs logiques, de comparaison et ensembliste.
Pour plus de détail sur ce language consultez la documentation Elasticsearch-dsl
Veuillez trouver au lien suivant des exemples de recherche avancée
Note
L’algorithme de découpage et de filtrage dans Elasticsearch est personnalisable pour chaque clé. Il suffit pour cela de définir le mapping convenablement.
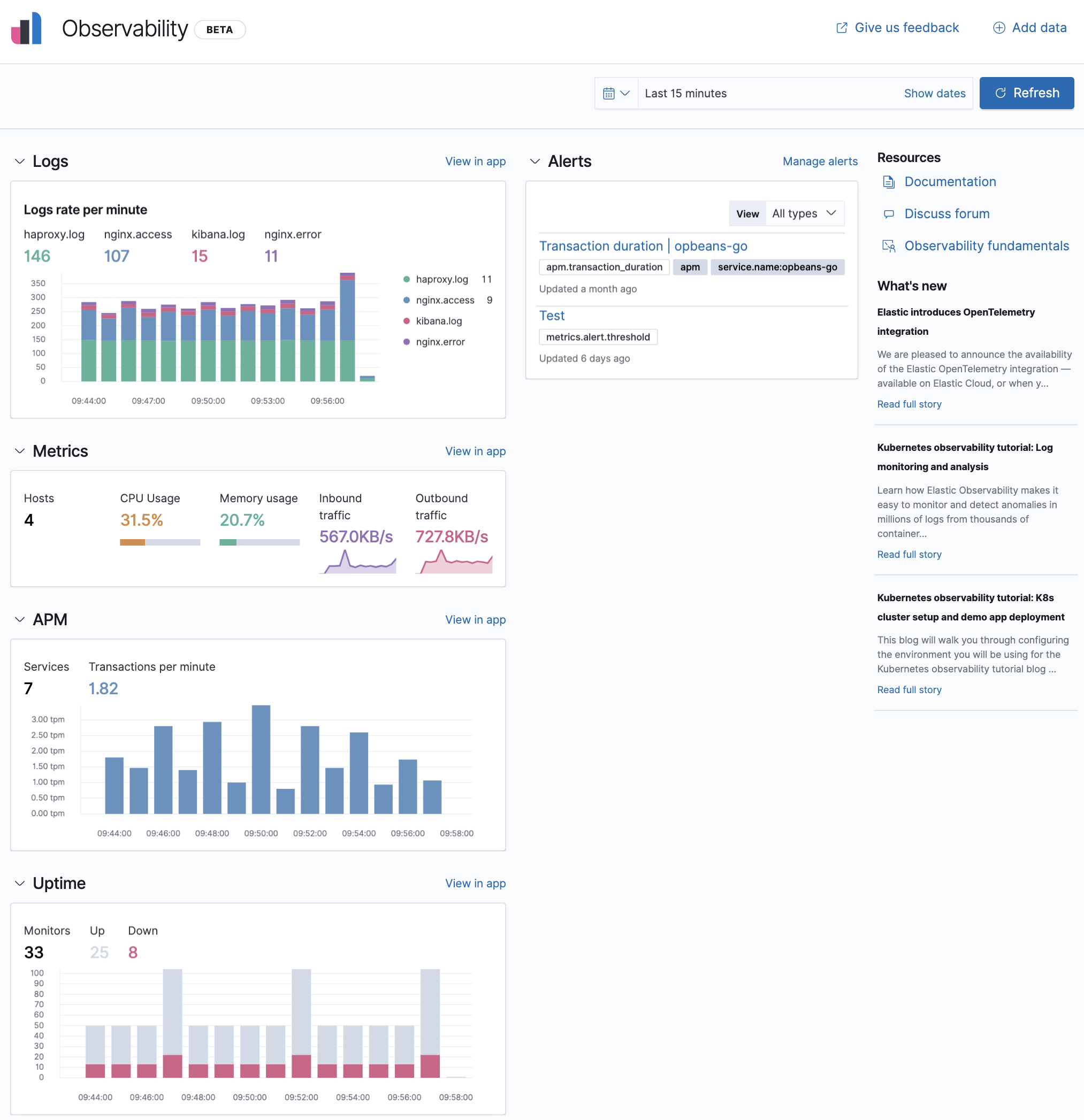
Un guide est proposé par la société elastic.co sur la mise en place d’un dashboard.
Exemple de tableau de bord Kibana :
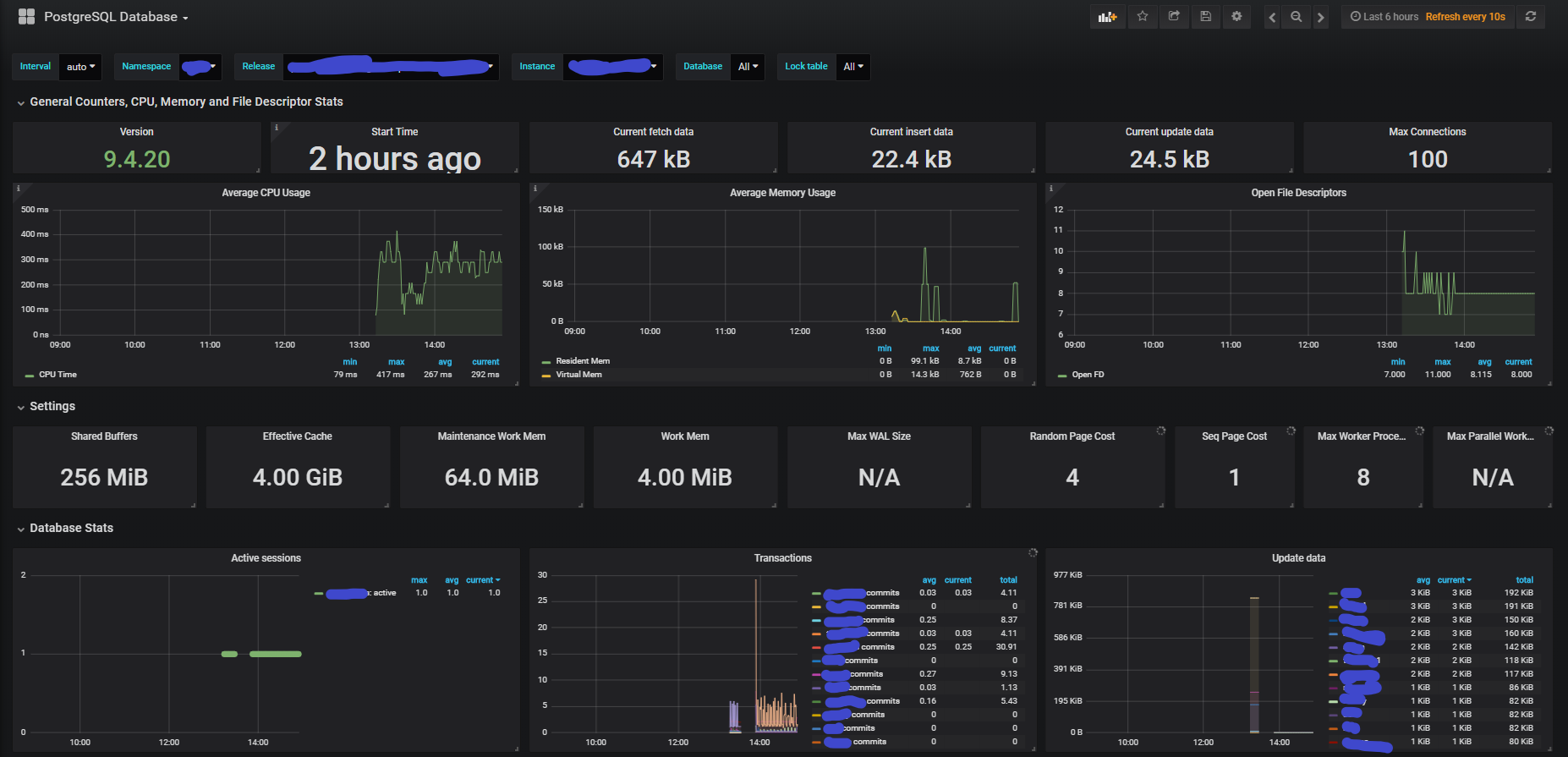
Grafana vous propose des modèles (template) de dashboards de performance pour la supervision d’applications connues comme nginx, redis et bien d’autres.
Exemple de tableau de bord Grafana :
Superviser votre machine
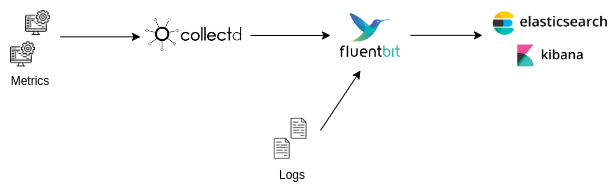
Pour superviser vos machines, vous pouvez collecter différents métriques et des logs en utilisant respectivement :
Collectd, un outil permettant de collecter diverses métriques ;
Fluentbit, un outil léger de gestion des logs.
Les données peuvent ensuite être envoyées par FluentBit vers Elasticsearch afin de pouvoir les consulter comme le montre le schéma ci-dessous :
Attention
Vous êtes responsable des données que vous insérer dans Elasticsearch. Merci de vous assurer d’avoir défini le cycle de vie de vos données au préalable.
Il est également conseillé de créer plusieurs index. Par exemple dans le cas d’utilisation défini dans cette documentation il est nécessaire de créer des index Collectd et FluentBit.
Installation
La procédure d’installation dépend de votre système d’exploitation, aussi il faudra consulter la documentation d’installation de Collectd et choisir la méthode adapté.
La procédure d’installation dépend de votre système d’exploitation, aussi il faudra consulter la documentation d’installation de Fluentbit et choisir la méthode adapté.
Configuration
Pour notre exemple nous allons utiliser des plugins collectd installés par défaut au moment de l’installation.
Afin de déployer un plugin collectd, il faut crééer un fichier de configuration comme ceci dans /etc/collectd/plugins.
Pour utiliser le plugin memory par exemple, nous allons créer le fichier /etc/collectd/plugins/memory.conf avec le contenu suivant :
<Plugin "memory">
ValuesAbsolute true
ValuesPercentage true
</Plugin>
et le fichier de configuration pour le fichier network /etc/collectd/plugin/network.conf avec le contenu suivant :
<Plugin "network">
Server "127.0.0.1" "25826"
</Plugin>
Nous allons rediriger la sortie du plugin memory vers l’adresse localhost sur le port par défaut qui est le 25826.
Il faut ensuite vérifier que les lignes LoadPlugin memory et LoadPlugin network sont présentent dans le fichier /etc/collectd/collectd.conf.
Nous démarrons ensuite le service :
% sudo systemctl restart collectd.service
Pour vérifier que tous s’est bien passé nous pouvons consulter les logs avec la commande :
% journalctl -xe
Enfin pour tester que les données sont bien exposées sur le port choisi nous pouvons lancer la commande suivante :
% nc -ul 25826
Il existe 4 sections de configuration fluentbit : SERVICE, INPUT, FILTER and OUPUT
Les données sont traitées sous forme de pipeline comme ceci :
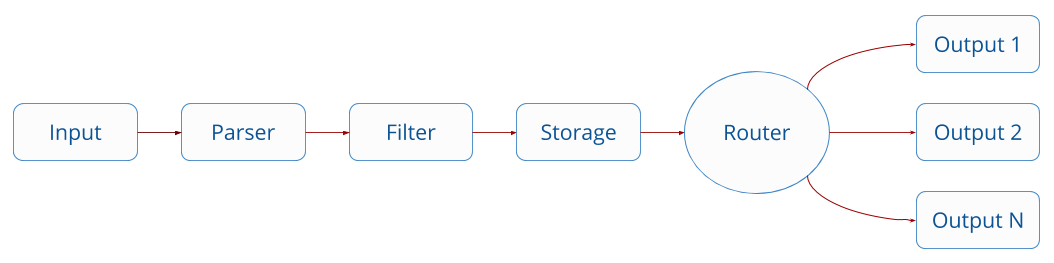
Pour plus d’informations vous pouvez consulter la documentation du fichier de configuration.
Le fichier principal de configuration se trouve ici :
/etc/fluent-bit/fluent-bit.conf
Il est possible de créer plusieurs fichiers de configuration et de les inclures au fichier principal en ajoutant la ligne :
@INCLUDE myConfFile.conf
Pour tester vos fichiers de configuration vous pouvez utiliser l’outil de visualisation Calyptia.
Exemple de configuration avec l’input tail qui fonctionne comme la commande tail -f pour lire la fin d’un fichier et un input qui va récupérer les données générées par collectd :
# Le champ service défini différents paramètres de FluentBit
[SERVICE]
flush 1
daemon Off
log_level debug
log_file /var/log/fluent-bit.log
parsers_file parsers.conf
plugins_file plugins.conf
http_server Off
http_listen 0.0.0.0
http_port 2020
storage.metrics on
# Le champ input défini les données en entré de FluentBit
[INPUT]
Name tail
Tag zeppelin.log
Path /path/to/my/logfile/zeppelin.log
Parser zeppelin
# Le champ filter permet de filtrer des données en utilisant divers modules comme ici modify qui permet d'ajouter le nom du service aux données
[FILTER]
Name modify
Match zeppelin.log
Add service zeppelin
# Le champ output défini la destination des données
[OUTPUT]
Name stdout
Match *
[OUTPUT]
Name es
Match *.log
Host elias-beta.cc.in2p3.fr
Port 9200
Index indexname
tls On
tls.verify Off
tls.ca_file /path/to/ca.crt
tls.crt_file /path/to/client.crt
tls.key_file /path/to/client.key
# La commande @INCLUDE permet d'inclure le contenu d'un fichier de configuration
@INCLUDE /etc/fluent-bit/collectd.conf
Ce fichier contient la configuration pour utiliser les données de Collectd en entrée pour FluentBit. Nous utilisons le plugin dédié avec le champ Name. https://docs.fluentbit.io/manual/pipeline/inputs/collectd
[INPUT]
Name collectd
Tag collectd
Listen 0.0.0.0
Port 25826
TypesDB /usr/share/collectd/types.db,/etc/collectd.d/custom-types.db
Nous ajoutons un parser spécifique à notre fichier de log dans le fichier parsers.conf. Pour vérifier vos regex vous pouvez les tester avec cet outil : https://cloud.calyptia.com/regex
[PARSER]
Name zeppelin
Format regex
Regex ^(?<log_level>[^ ]+) \[(?<timestamp>[^\]]+)\] (?<class_name>[^ ]+ [^ ]+) - (?<message>.*)$
Time_Key timestamp
Time_Format %Y-%m-%d %H:%M:%S,%L
Time_Keep On
Time_Offset +0200