Dask usage
The package dask4in2p3 may be found in the GitLab project Dask4in2p3. It enables a CC-IN2P3 Jupyter Notebook Platform user to run one or more tasks on the CC-IN2P3 computing platform.
Important
While it opens a connection to the computing servers, Dask IS NOT an alternative tool to submit jobs on the computing platform. Please refer to the dedicated section if this is your objective.
The computing ressource used by Dask tasks will be deducted from the annual computing group allocated HTC ressource.
Prerequisites
To enable this feature, dask4in2p3 needs to be installed in two separated places. On the computing servers nodes running the dask-workers, in a dedicated conda environment on one hand, and in the Jupyter Notebooks server side on the other hand.
The package dask4in2p3 is already installed in the Docker image of your notebooks server. For more details and some usage exemples, please refer to the Gitlab projects:
Using your conda environment
When using your own conda environment, you will have to install the package dask4in2p3. Please check the package dependencies if you will use your virtual environment to create a custom kernel.
Important
Please take into account Anaconda usage recommendations.
Attention
If you are using a custom kernel, you need to declare your virtual environment path, when creating the dask4in2p3 object:
# Importing the class from the module (package.module)
from dask4in2p3.dask4in2p3 import Dask4in2p3
# Creating a Dask4in2p3 object (with a default Python virtual environment)
my_dask4in2p3 = Dask4in2p3()
Check DemoDask4in2p3
To install the latest version:
% export dask4in2p3_pkg="git+https://git:glpat-Fv9xw_OFIhRMeO2ksrP60G86MQp1OmRoNQk.01.0z1vpx2xw@gitlab.in2p3.fr/dask_for_jnp/dask4in2p3.git"
% python -m pip install "${dask4in2p3_pkg}"
Features
The dask-scheduler and the dask-workers will be running on our computing platform. The dask-client, running in your notebooks server, will be connected to the dask-scheduler.
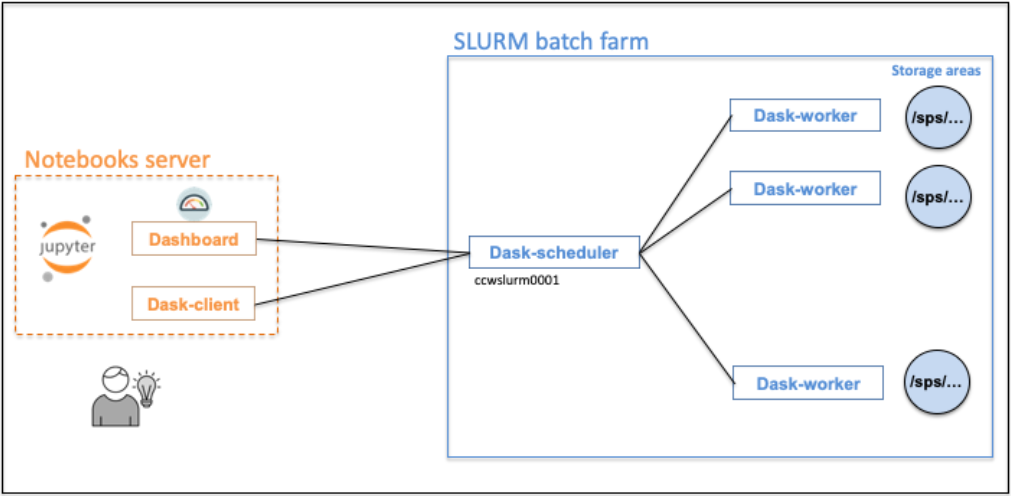
Attention
HPC or GPU jobs will not be allowed through the Dask functionality.
Getting a dask-client
To get a dask-client, you will have to wait for the dask-worker jobs being in RUNNING status.
Note
To avoid a long wait when requesting large amount of dask-worker jobs, the parameter dask_worker_wait_for_running_percent allows you to specify the percentage of RUNNING dask-worker jobs to reach before providing a connected dask-client.
By setting the value to 0 you will fully bypass this waiting phase, providing a dask-client in the quickest way.
Cancelling computing tasks
Computing tasks are automatically cancelled when stopping the notebooks server, by selecting File > Log Out.
Nevertheless it’s possible to cancel tasks from your Jupyter notebook via the close() method.
my_dask4in2p3 = Dask4in2p3()
...
# This will cancel the dask-scheduler and all the dask-worker batch jobs
my_dask4in2p3.close()
Time limits
The task’s duration (option --time for the job scheduler) can be set for both the dask-scheduler and the dask-worker jobs via respectively the parameters dask_scheduler_time (default 8 hours) and dask_worker_time (default 2 hours).
The idle_timeout (default 2 hours), is the time of inactivity after which the dask-scheduler and consequently the dask-workers will stop.
Logging messages
The jobs stdout and stderr are written in the log/ directory of the current working area. There is one file per job. Since logging is useful to help debugging, a ready-to-use logger is available via the get_logger() method.
my_logger = my_dask4in2p3.get_logger()
my_logger.info("Processing data files ...")
When used in Python code part processed on dask-workers, the messages will be sent to the job stdout files.
Limitations
The scale method is not available
To get more or less tasks, you have to re-run new_client() which will launch a new dask-scheduler and new dask-worker jobs (after deleting your previously running jobs related to Dask).
Maximum number of dask-worker jobs
This number is principally related to the number of available slots in the computing platform. This depends on several factor like the group resources allocation, the number of simultaneous users, the current global load of the computing platform, etc.
Internal tests were carried out with 2500 jobs (= 2500 dask-workers) for a single user.