Utilisation de Dask
Le module daskslurm est disponible via le projet GitLab DaskSlurm (une authentification à GitLab est requise pour accéder à la page du projet). Il permet à un utilisateur de la plateforme Jupyter Notebooks du CC-IN2P3 de distribuer des tâches de calcul sur la plateforme de calcul du CC-IN2P3.
Important
Bien qu’il ouvre une connexion aux serveurs de calcul, Dask N’EST PAS un outil alternatif pour soumettre des jobs sur la plateforme de calcul. Veuillez vous référer à la section dédiée si nécessaire.
Les ressources de calcul utilisées par les tâches Dask seront déduites de la ressource HTC allouée au groupe pour l’année en cours.
Veuillez trouver ici une collection d’exemples dédiés à cette utilisation

Installation
Le module daskslurm est installé dans les deux noyaux scientifiques fournis par défaut. Par contre, si vous utilisez un noyau personnalisé, vous devrez l’y ajouter.
Attention
Le module daskslurm nécessite au minimum la version Python 3.11. Veuillez adapter votre environnement virtuel en conséquence.
Pour installer le module daskslurm :
% export daskslurm_package_registry="https://__token__:gldt-Jziuo-bHMVzJcrPV-8Wz@gitlab.in2p3.fr/api/v4/projects/36268/packages/pypi/simple"
% python -m pip install --extra-index-url "${daskslurm_package_registry}" daskslurm=='0.1.3'
Note
Veuillez vous référer au projet GitLab DaskSlurm pour vérifier les versions disponibles, et sélectionner la dernière.
Fonctionnalités
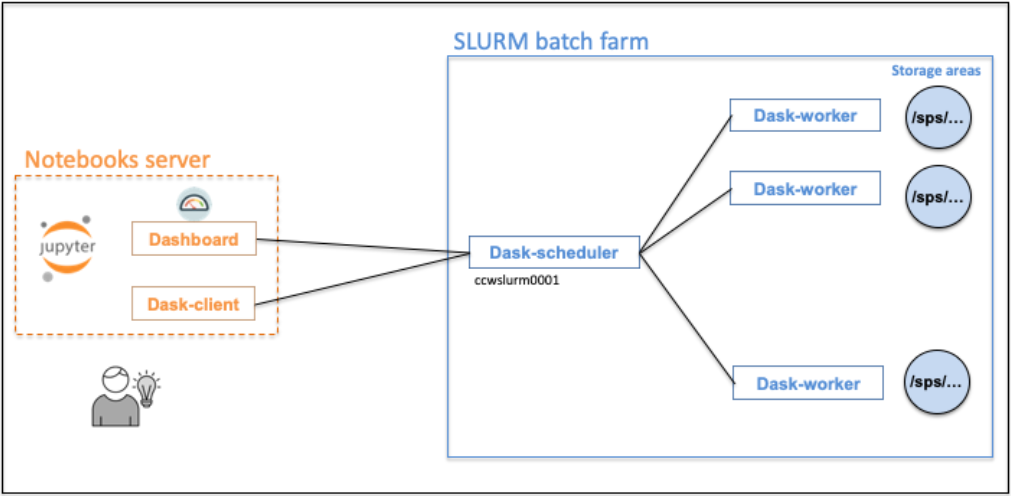
Les dask-workers s’exécuteront sur notre plateforme de calcul. Le client dask, fonctionnant sur votre serveur de notebook, sera connecté au dask-scheduler.
Attention
Les jobs HPC ne seront pas autorisées par la fonctionnalité Dask.
Obtenir un client dask
Pour obtenir un client dask, vous devez attendre que les tâches du dask-worker soient en état RUNNING.
import daskslurm
from daskslurm.cluster import DaskSlurmCluster
my_daskslurm_cluster = DaskSlurmCluster()
Annulation des tâches de calcul
Les tâches de calcul sont automatiquement annulées lors de l’arrêt du serveur de notebook, en sélectionnant File > Log Out.
Néanmoins, il est possible d’annuler les tâches depuis votre notebook Jupyter via la méthode close().
my_daskslurm_cluster = DaskSlurmCluster()
...
my_daskslurm_cluster.close()
Paramètres par défaut (modifiables) relatifs aux tâches de calcul
dask_worker_jobspar défaut :1job, valeur max :3000;
dask_worker_memorypar défaut :3G, valeur max :32G;
dask_worker_corespar défaut :1CPU, valeur max :32;
dask_worker_timepar défaut :02:00:00(2 heures), valeur max :48:00:00(2 jours);Voir la docstring du constructeur
DaskSlurmCluster(...)pour la liste complète des paramètres.
Messages de log
Les STDOUT et STDERR des jobs sont écrits dans le répertoire log/ de l’espace de travail courant. Il y a un fichier par job. Puisque la journalisation est utile pour aider au débogage, un logger prêt à l’emploi est disponible via la méthode get_logger().
# get_logger available as function
from daskslurm.cluster import get_logger
my_logger = get_logger()
my_logger.info("Processing data files ...")
Lorsqu’il est utilisé dans une partie de code Python traitée sur des dask-workers, les messages seront envoyés aux fichiers stdout du job.
Méthode scale()
La méthode scale() permet d’augmenter, ou de diminuer, le nombre de dask-workers sans recréer un DaskSlurmCluster.
my_daskslurm_cluster = DaskSlurmCluster()
# Scale to 10 dask-worker job(s)
my_daskslurm_cluster.scale(jobs=10)
Limitations
Nombre maximum de jobs du dask-worker
Ce nombre est principalement lié à la disponibilité de la plateforme de calcul. Il dépend de plusieurs facteurs tels que l’allocation des ressources pour un groupe, le nombre d’utilisateurs simultanés, la charge globale actuelle de la plateforme de calcul, …
Des tests ont pu être réalisés avec 2500 jobs (soit 2500 dask-workers) pour un seul utilisateur.